




Final: Question 2
Please use the Enron dataset you imported for the previous problem. For this question, you will use the aggregation framework to figure out pairs of people that tend to communicate a lot. To do this, you will need to unwind the To list for each message.
This problem is a little tricky because a recipient may appear more than once in the To list for a message. You will need to fix that in a stage of the aggregation before doing your grouping and counting of (sender, recipient) pairs.
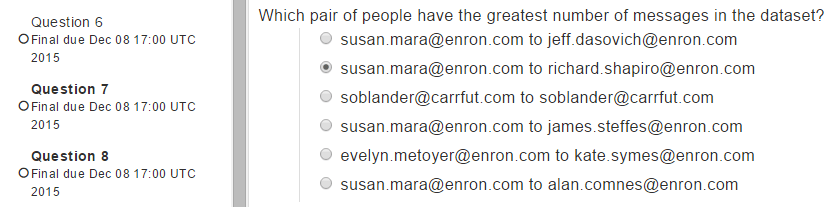
Which pair of people have the greatest number of messages in the dataset?
Solution: Query to run as per the question is below as per my understanding:
db.messages.aggregate([
{$project: {
from: "$headers.From",
to: "$headers.To"
}},
{$unwind: "$to"},
{$project: {
pair: {
from: "$from",
to: "$to"
},
count: {$add: [1]}
}},
{$group: {
_id: "$pair",
count: {$sum: 1}
}},
{$sort: {
count: -1
}},
{$limit: 2},
{$skip: 1}
])
Results that I found is below:
{ "_id" : { "from" : "susan.mara@enron.com", "to" : "richard.shapiro@enron.com" }, "count" : 974 }
Let me know if you guys find extra so that we can discuss it.
Thanks





